

Abstract
Global insights into cellular organization and genome function require comprehensive understanding of the interactome networks that mediate genotype-phenotype relationships1,2. Here, we present a human “all-by-all” reference interactome map of human binary protein interactions, or “HuRI”. With ~53,000 high-quality protein-protein interactions (PPIs), HuRI has approximately four times more such interactions than high-quality curated interactions from small-scale studies. Integrating HuRI with genome3, transcriptome4, and proteome5 data enables the study of cellular function within most physiological or pathological cellular contexts. We demonstrate the utility of HuRI in identifying specific subcellular roles of PPIs. Inferred tissue-specific networks reveal general principles for the formation of cellular context-specific functions and elucidate potential molecular mechanisms underlying tissue-specific phenotypes of Mendelian diseases. HuRI represents a systematic proteome-wide reference linking genomic variation to phenotypic outcomes.
The reference human genome sequence has enabled systematic study of genetic6 and expression4 variability at the organism6, tissue4, cell type7 and single cell level8. Despite advances in sequencing genomes, transcriptomes, and proteomes, we still understand little about the cellular mechanisms that mediate phenotypic and tissue or cell type variability. A mechanistic understanding of cellular function and organization emerges from studying how genes and their products, primarily proteins, interact with each other, forming a dynamic interactome that drives biological function. Analogous to the reference human genome sequence9,10, a reference map of the human protein interactome, generated systematically and comprehensively, is needed to provide a scaffold for the unbiased proteome-wide study of biological mechanisms, generally and within specific cellular contexts.
It remains infeasible to assemble a reference interactome map by systematically identifying endogenous PPIs in thousands of physiological and pathological cellular contexts11,12. However, systematic affinity purification of exogenously expressed bait proteins in immortalized-cell contexts13 as well as binary PPI detection assays in cell models2,14 have generated biophysical human protein interactome maps of demonstrated high functional relevance. Specifically, yeast two-hybrid (Y2H) represents the only binary PPI assay that can be operated at sufficient throughput to systematically screen the human proteome for binary PPIs. Using Y2H followed by validation in orthogonal assays, we previously generated HI-II-14 consisting of ~14,000 PPIs involving 4,000 proteins from screening ~40% of the genome-by-genome search space2. In contrast to curated interactions from hypothesis-driven small-scale studies and protein complex interactome maps favoring highly expressed proteins, HI-II-14 covers the proteome more uniformly and is relatively free from ascertainment and expression biases.
To increase interactome coverage and generate a reference map of human binary PPIs, we expanded the ORFeome collection to encompass ~90% of the protein-coding genome. We screened this search space a total of nine times with a panel of three Y2H assay versions (Fig. 1a, b). The resulting PPI map quadruples the number of identified PPIs overall, and upon integration with genome, transcriptome and proteome resources enables biological discovery across most cellular contexts, offering a reference map of the binary human protein interactome.
Fig. 1 |. Generation of a reference interactome map using a panel of binary assays.
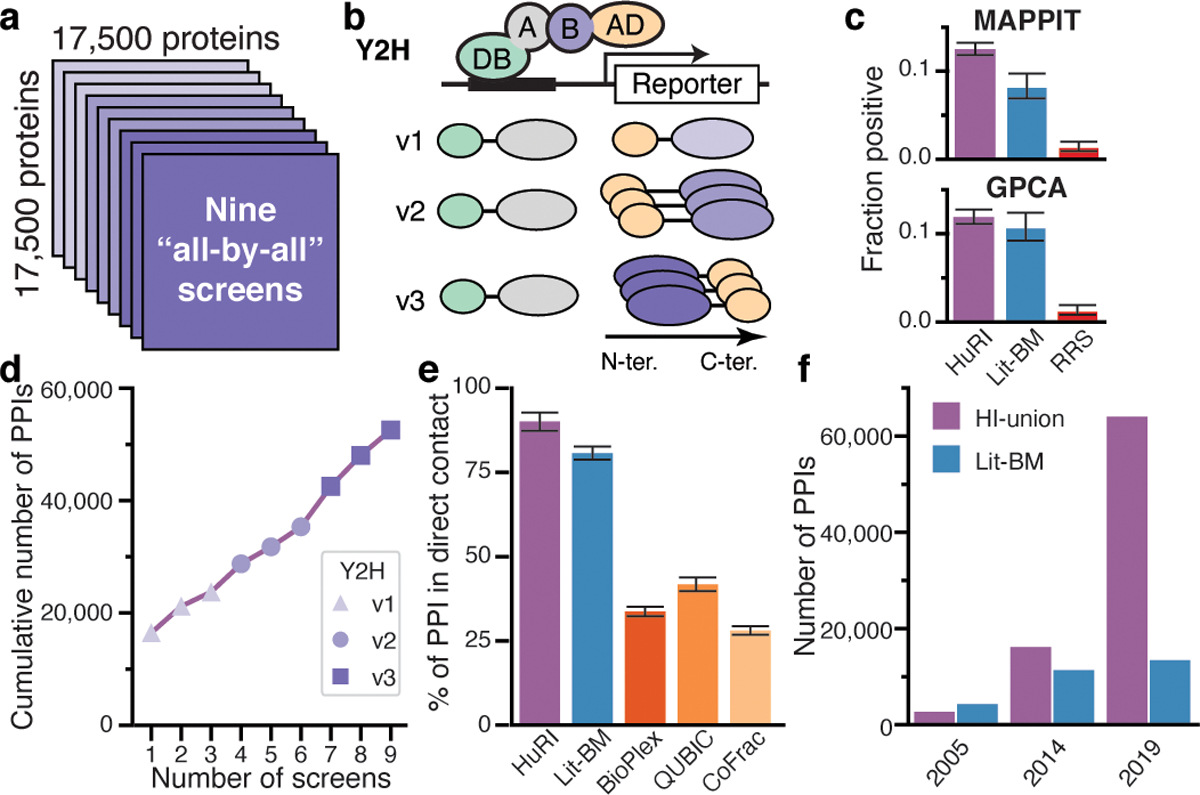
a, Overview of HuRI generation. b, Schematic of the Y2H assay versions. c, Experimental validation. Lit-BM: literature-curated binary PPIs with multiple evidence; RRS: random protein pairs. Error bars are 68.3% Bayesian confidence interval, n = 2,281, 383, 475 (MAPPIT) 1,639, 382, 465 (GPCA). d, Number of PPIs and proteins, detected with each additional screen. e, Fraction of direct contact pairs among five PPI networks. Error bar is standard error of proportion, n = 121, 410, 1,169, 584, 1,211 PPIs. f, Number of PPIs identified over time from screening at CCSB and Lit-BM.
Generation and characterization of HuRI
The newly established human ORFeome v9.1 covers 17,408 protein-coding genes (Extended Data Fig. 1a, b, Supplementary Table 1, 2), forming a search space (Space III) that encompasses over 150 million pairwise combinations (Fig. 1a). This search space more than doubles the space screened to generate HI-II-14 and represents the most comprehensive search space systematically screened for human PPIs. Limitations in PPI assay sensitivity can be overcome by using different assays15,16 or different versions of the same assay17,18. To maximize sensitivity we used three Y2H assay versions (Fig. 1b, Supplementary Table 3, 4) that showed good sensitivity and low false positive rates when benchmarked against gold-standard positive and random reference sets (PRSv1 and RRSv1, respectively)15, while detecting complementary PPI sets (Extended Data Fig. 1c, d, Supplementary Table 5). We assessed assay performance using a test space of ~2,000 by ~2,000 human genes2 (Extended Data Fig. 1e, Supplementary Table 6). The Y2H versions were complementary, in that three screens for each of three versions doubled the number of detected PPIs and proteins relative to nine screens using a single version (Extended Data Fig. 1f, Supplementary Table 7).
To map the reference interactome, we performed nine screens of Space III, followed by pairwise verification by quadruplicate retesting and sequence confirmation. PPIs verified by two orthogonal binary PPI assays, MAPPIT19 and GPCA20, were recovered at rates on par with high-confidence binary PPIs from the literature (each having ≥2 pieces of experimental evidence, with at least one from a binary assay type; Lit-BM) over a large range of score thresholds (Fig. 1c, Extended Data Fig. 1g, h, Supplementary Table 8). Each additional screen identified novel PPIs and proteins, with the largest gains obtained by switching assay versions (Fig. 1d, Extended Data Fig. 1i). The dataset, versioned HI-III-20 (Human Interactome obtained from screening Space III, published in 2020), contains 52,569 verified PPIs involving 8,275 proteins (Supplementary Table 9). Although our knowledge of the interactome remains incomplete, we refer to HI-III-20 as a reference map of the human binary protein interactome (HuRI) given its systematic nature, extensive coverage, and scale.
Molecular mechanisms can be more readily inferred from direct than indirect PPIs, yet the fraction of PPIs reported in various human protein interactome maps that are direct remains unknown. Structures from protein complexes with at least three subunits21 show that, within those complexes, more PPIs in HuRI correspond to direct biophysical contacts than do PPIs from Lit-BM (90% vs. 81%, P = 0.019, two-sided Fisher’s exact test, n = 121 and 410 for HuRI and Lit-BM, respectively) or from protein complex interactome maps (< 50%, P < 0.001 for all tested maps, two-sided Fisher’s exact test; Fig. 1e, Supplementary Table 10). Combining HuRI with all previously published systematic screening efforts at CCSB yields 64,006 binary PPIs involving 9,094 proteins (HI-union; Supplementary Table 11), which is approximately five-fold more PPIs than the entirety of high-quality binary PPIs curated from the literature (Fig. 1f, Extended Data Fig. 2, Supplementary Table 12–14). The union of Lit-BM and HI-union represents the most complete collection of high-quality direct PPI data available to date (http://interactome-atlas.org).
Complementarity of the three Y2H versions might stem from steric constraints that differ between protein fusions used in the assays. Integrating HuRI with structures of PPIs21, we observed reduced sensitivity of Y2H assays where the interaction interface was close (< 20Å) to whichever terminus was fused to the Gal4 activation domain (AD; Extended Data Fig. 3a, b, Supplementary Table 15). PPIs found in multiple screens had larger interaction interfaces (P = 0.03, two-sided permutation test, n = 234) and corresponded more often to direct PPIs within, rather than between, protein complexes (P = 3 × 10−18, two-sided Fisher’s exact test, n = 1,817), however, HuRI PPIs found in a single screen were observed to have precision as high as those found in multiple screens (Extended Data Fig. 3c–g, 4, Supplementary Table 16–18, Supplementary Note 1). These results reinforce previous observations12,22 that the protein interactome might be dominated by weaker and more transient PPIs that are difficult to detect, as indicated by the fact that the majority of PPIs in HuRI were found in only one screen (Extended Data Fig. 3h, i). This is reflected in an increased estimate of the binary protein interactome size (Extended Data Fig. 3j), so that HuRI is estimated to represent 2–11% of the binary protein interactome23 (Supplementary Note 2).
Functional relationships in HuRI
Based on the observation that HuRI is enriched in direct PPIs, we also hypothesize that proteins in HuRI with similar interaction interfaces tend to share interaction partners. For example, retinoic acid receptors RXR-γ and -β (Extended Data Fig. 5a, left panel) share previously reported interaction partners involving binding to retinoic acid receptor RAR types24 and oxysterol receptors NR1 group H types25. We derived a profile similarity network (PSN) from HuRI (Supplementary Table 19), and found that the number of pairs of proteins in HuRI with similar interaction profiles is higher than random (P < 0.01, one-sided empirical test; Extended Data Fig. 5b) and proteins of overall higher sequence identity tend to exhibit higher interaction profile similarities (P < 0.01, one-sided empirical test; Extended Data Fig. 5c). We also found that proteins with a tendency to share interaction partners often have interaction interfaces that are similar, as opposed to complementary, and therefore tend not to interact with one another, except where proteins originate from a common ancestor that could self-interact26 (Extended Data Fig. 5d). Indeed, only 5% of the protein pairs found to interact in HuRI share more than 10% of their interaction partners. Both HuRI PPIs and the PSN are enriched for links between proteins of similar function (P < 0.01, one-sided empirical test; Fig. 2a, Supplementary Table 20, Extended Data Fig. 5e, f) and both contain more functional modules27 than our previously published interactome maps2,14 (Fig. 2b, Extended Data Fig. 5g). Thus, HuRI and the PSN are complementary maps of functional relationships between proteins.
Fig. 2 |. Complementary functional relationships in HuRI between genes.
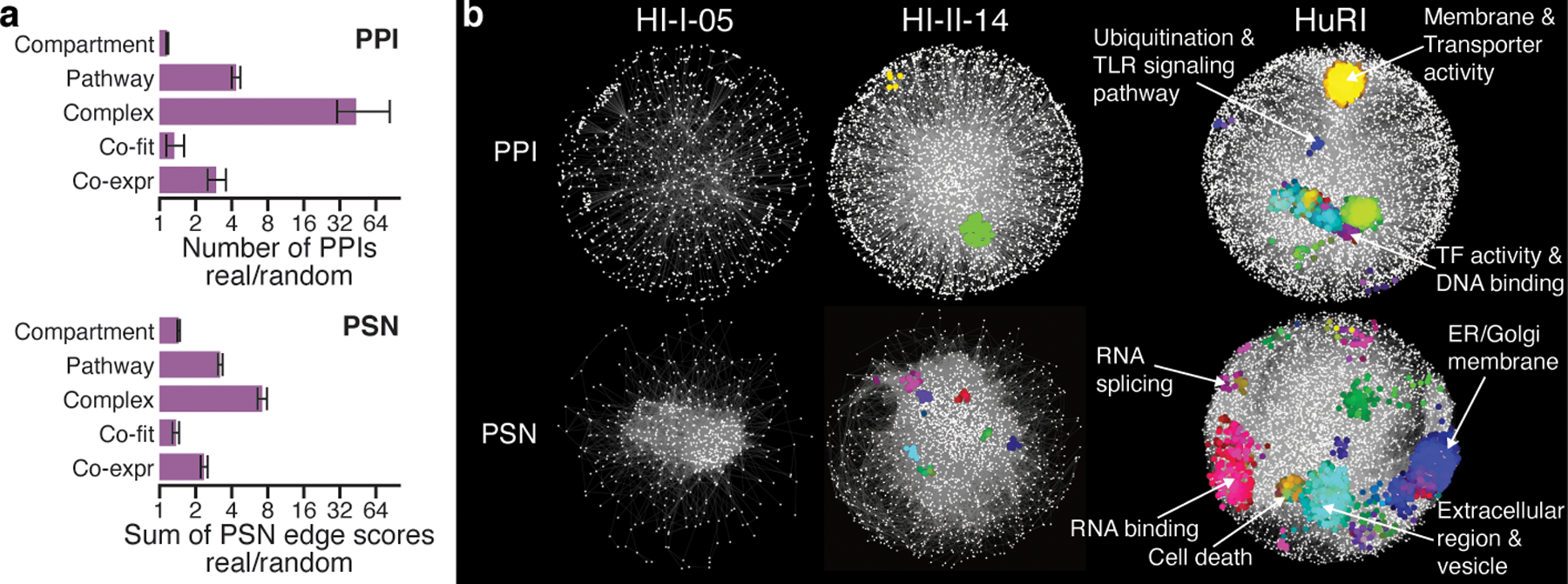
a, Enrichment of HuRI and its profile similarity network (PSN) for protein pairs with shared functional annotation, showing mean and 95% interval of 100 random networks. b, Functional modules in HuRI and its PSN and in previously published interactome maps from CCSB.
As shown above, global sequence identity between two proteins can be indicative of shared interaction interfaces, however, it likely fails to identify pairs of proteins whose shared interaction interface is small. Indeed, 50% (502) of all protein pairs in HuRI with interaction profile similarities ≥ 0.5 exhibit ≤ 20% sequence identity, so that functional relationships identified by the PSN are not necessarily identifiable by sequence identity. One such protein pair is the endoplasmic reticulum (ER) transmembrane protein TMEM258 and the uncharacterized protein C19ORF18, which have only 10% sequence identity but share 80% of their interactors (Extended Data Fig. 5a, right panel). TMEM258 catalyzes the first step in N-glycosylation of proteins in the ER and might play a role in protein translocation across the ER28. Roles in protein transport and ER function have also been ascribed to two of the four shared interaction partners, ARL6IP129 and IER3IP130, suggesting that C19ORF18 and potentially the other two shared interaction partners (MFSD6 and AC012254.2) contribute to ER-related functions of protein maturation and transport.
Uncharted disease-related interactions
Unlike Lit-BM, HuRI was generated by systematically testing protein pairs for interaction. While Lit-BM is highly biased towards the most studied genes2, HuRI covers the genome-by-genome space more uniformly and at increased depth compared to Lit-BM and our previous screening efforts (Fig. 3a, Extended Data Fig. 5h). Interestingly, we find that the agreement between Lit-BM and HuRI is highest among the best-studied genes, where Lit-BM is most complete and where ~40% of the PPIs in HuRI have been previously identified (Fig. 3b). HuRI substantially expands the number of biomedically interesting genes for which high-quality direct PPI data is available (Fig. 3c, Extended Data Fig. 5i), and finds new interaction partners for these genes in previously uncharted regions of the protein interactome (Fig. 3d, Extended Data Fig. 5j).
Fig. 3 |. Unbiased proteome coverage of HuRI reveals uncharted network neighborhoods of disease-related genes.
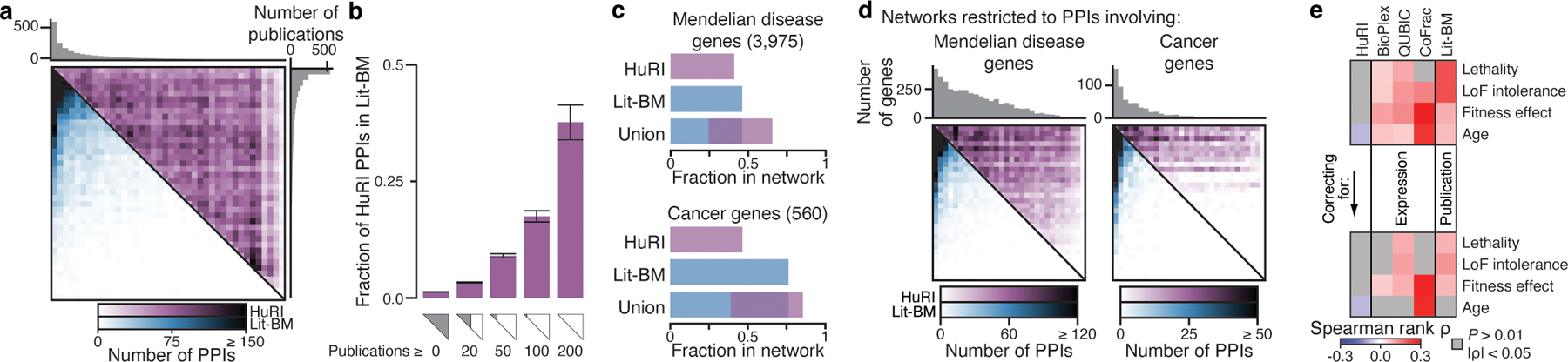
a, Heatmaps of Y2H PPI counts, ordered by number of publications. b, Fraction of HuRI PPIs in Lit-BM, for increasing values of the minimum number of publications per protein. Error bar is standard error of proportion, n = 52,569–170 PPIs. c, Fraction of genes with at least one PPI for biomedically interesting genes. d, As a, but restricted to PPIs involving genes from the indicated gene sets. e, Correlation between degree and variables of interest, before (top) and after (bottom) correcting for the technical confounding factors (n = 13,441–53,704 PPIs per network, two-tailed permutation test).
Essential proteins were often found to have significantly more interaction partners31. However, correlation between two variables does not necessarily imply causality, especially where there are other confounding variables (Extended Data Fig. 5k). We find that protein popularity (measured by publication count) and endogenous expression level strongly correlate with: i) each other; ii) the number of interaction partners (‘degree’) in protein complex and literature-curated protein interaction networks but not in HuRI; as well as iii) gene properties such as essentiality, age32, fitness effect33 and loss-of-function intolerance6 (Extended Data Fig. 5l, Supplementary Table 21). After correcting for popularity and expression level, we found substantially reduced correlations between interaction degree and other gene properties, including gene essentiality (Fig. 3e, Extended Data Fig. 5m, n). In line with previous observations34, this suggests that correlations between degree and essentiality, age, loss-of-function intolerance, and fitness effects are confounded by underlying expression and study biases, and thus may not reflect causal relationships. These results highlight the value of HuRI as a uniformly-mapped reference for the study of systems properties of genes and networks.
Compartment-specific roles of PPIs
Proteins are localized to specific compartments, carrying out functions that depend both on the subcellular environment and the local PPI network. Despite available proteome-wide datasets on the localization of individual proteins5, experimental determination of cellular localization-specific PPI networks remains challenging. We find that proteins localizing to a diverse range of subcellular compartments are evenly represented in HuRI (Extended Data Fig. 6a), suggesting that cellular localization-specific PPI networks can be inferred for many different cellular compartments via integration of HuRI with available protein localization data.
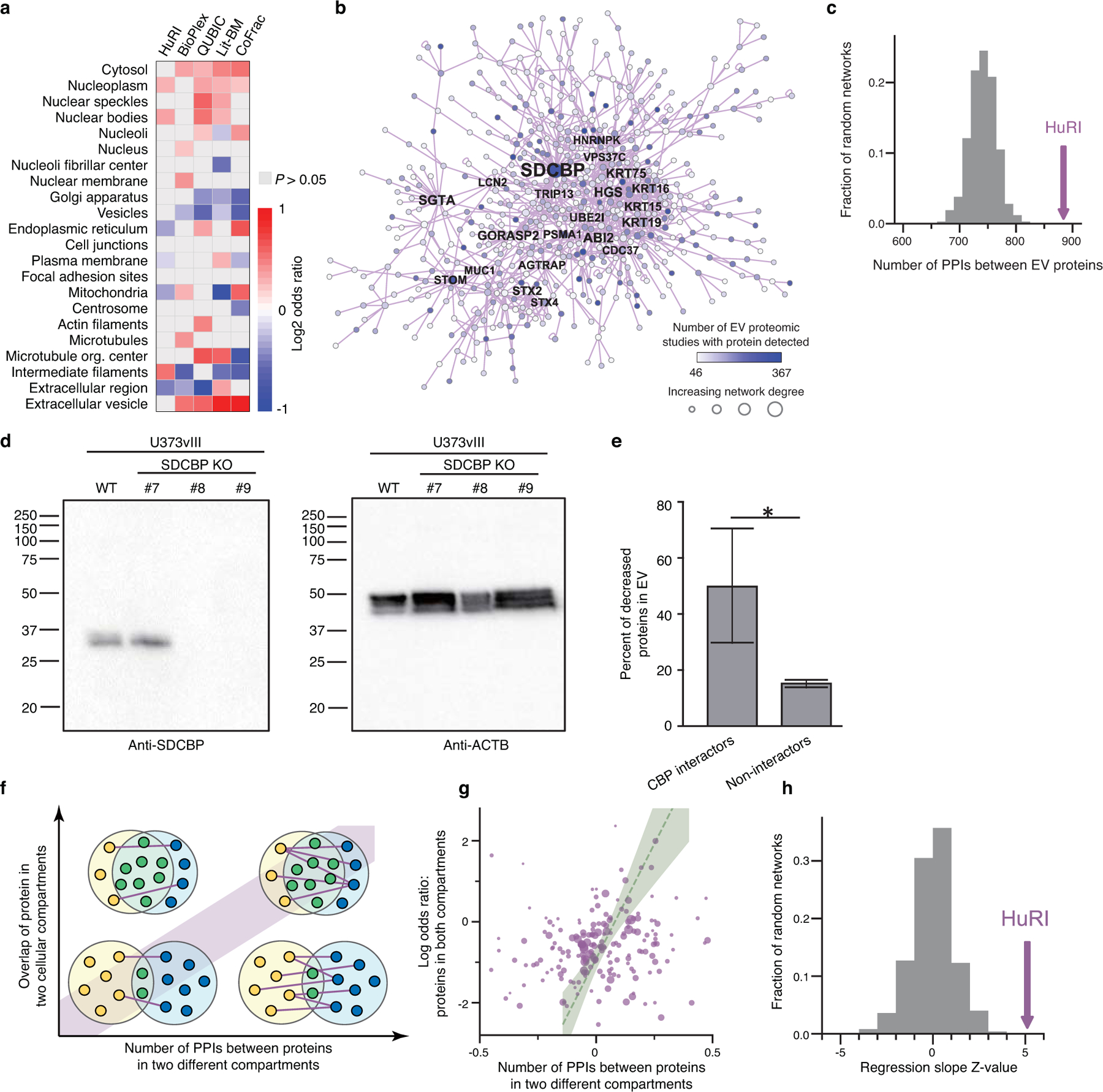
Extracellular vesicles (EVs) have been studied intensively using proteomics approaches35. However, our understanding of the molecular mechanisms that lead to protein recruitment into EVs and subsequent secretion remains limited. The subnetwork of interactions between EV proteins (Extended Data Fig. 6b) shows significantly higher connectivity in HuRI than in degree-controlled randomized networks (P < 0.001, one-sided empirical test; Extended Data Fig. 6c), enabling prediction of EV recruiters using the number of EV interaction partners. Seven of the top 21 most connected proteins in this EV network have established roles in EV biogenesis or cargo recruitment36. SDCBP (syntenin-1) functions in ESCRT-dependent EV generation and its knockout shows reduced EV production37. SDCBP has 48 PPIs with other EV proteins and is frequently detected in EVs, suggesting that it regulates recruitment of interacting proteins into EVs. To test this hypothesis (Fig. 4a), we knocked out SDCBP in the U373vIII cell line (Extended Data Fig. 6d). Of six SDCBP partners detected in the U373vIII EV proteome, three (CALM1, CEP55, HPRT1) displayed significantly reduced protein levels in EVs in the SDCBP knockout line (P < 0.05, one-sided empirical test, depletion < 0.66; Fig. 4b). In contrast, only 15% of the non-interaction partners of SDCBP were reduced (P = 0.042, one-sided empirical test; Extended Data Fig. 6e). Thus, SDCBP may play a role in the recruitment of proteins into EVs, highlighting the potential value of HuRI in studying protein function within specific subcellular contexts.
Fig. 4 |. Identification of potential recruiters of proteins into extracellular vesicles.
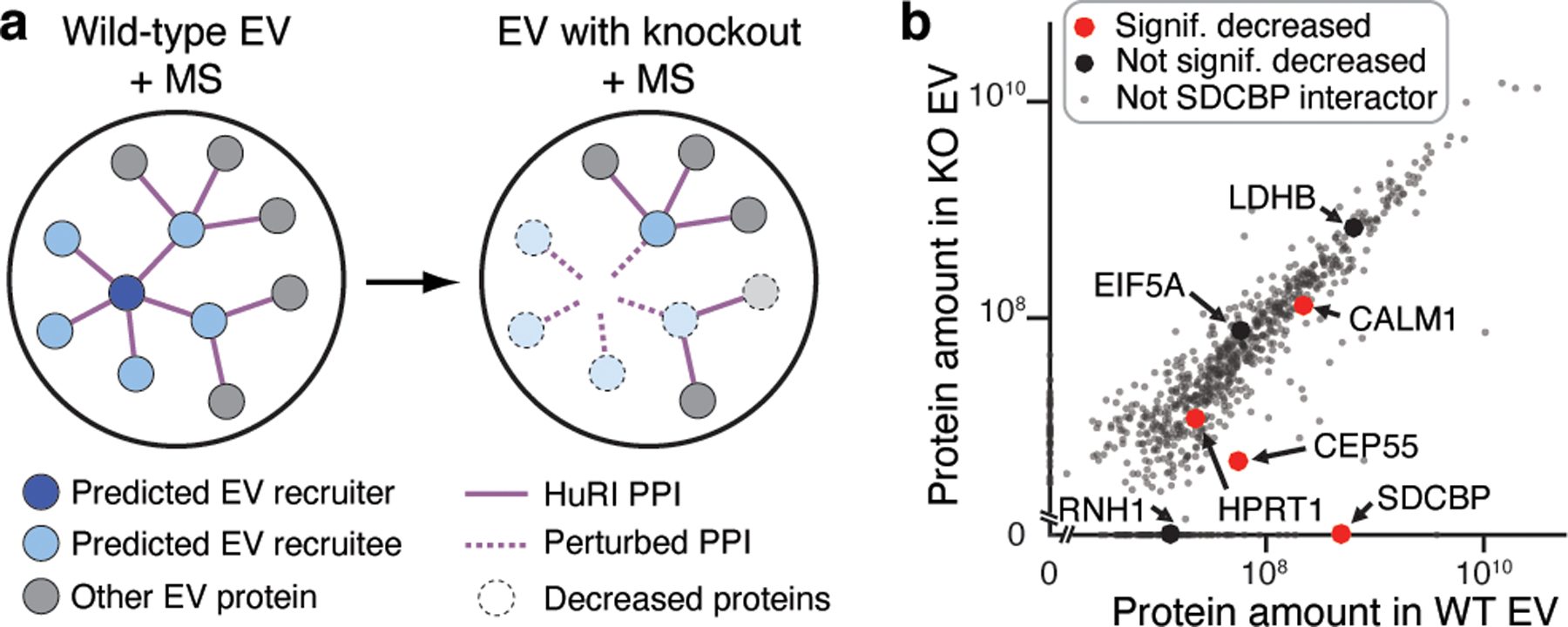
a, Schematic of experimental design to test EV recruitment function of proteins. MS: Mass Spectrometry. b, Protein abundance from EVs for each gene in WT (wild-type) and SDCBP KO (knockout). Mean values of n = 3 biological replicates.
Proteins often change subcellular localization, e.g. as part of their maturation process or in response to external or internal signaling events. These dynamics are difficult to comprehensively capture at proteome-scale, yet existing efforts have already revealed numerous proteins that localize to multiple subcellular compartments with some pairs of compartments exhibiting significantly more crosstalk than others5. Despite a tendency for interactions in HuRI to link proteins localized to the same compartment (P < 0.01, one-sided empirical test; Fig. 2a), a considerable number of interactions were identified between proteins never reported to co-localize. To explore whether lack of co-localization of interacting proteins in HuRI might originate from incomplete localization data, we assessed whether these non-co-localized interacting proteins tend to reside in compartments with significant crosstalk and observed a significant positive correlation (P < 0.001, one-sided empirical test; Extended Data Fig. 6f–h). This suggests that HuRI could prove useful in predicting protein localization dynamics.
Principles of tissue-specific function
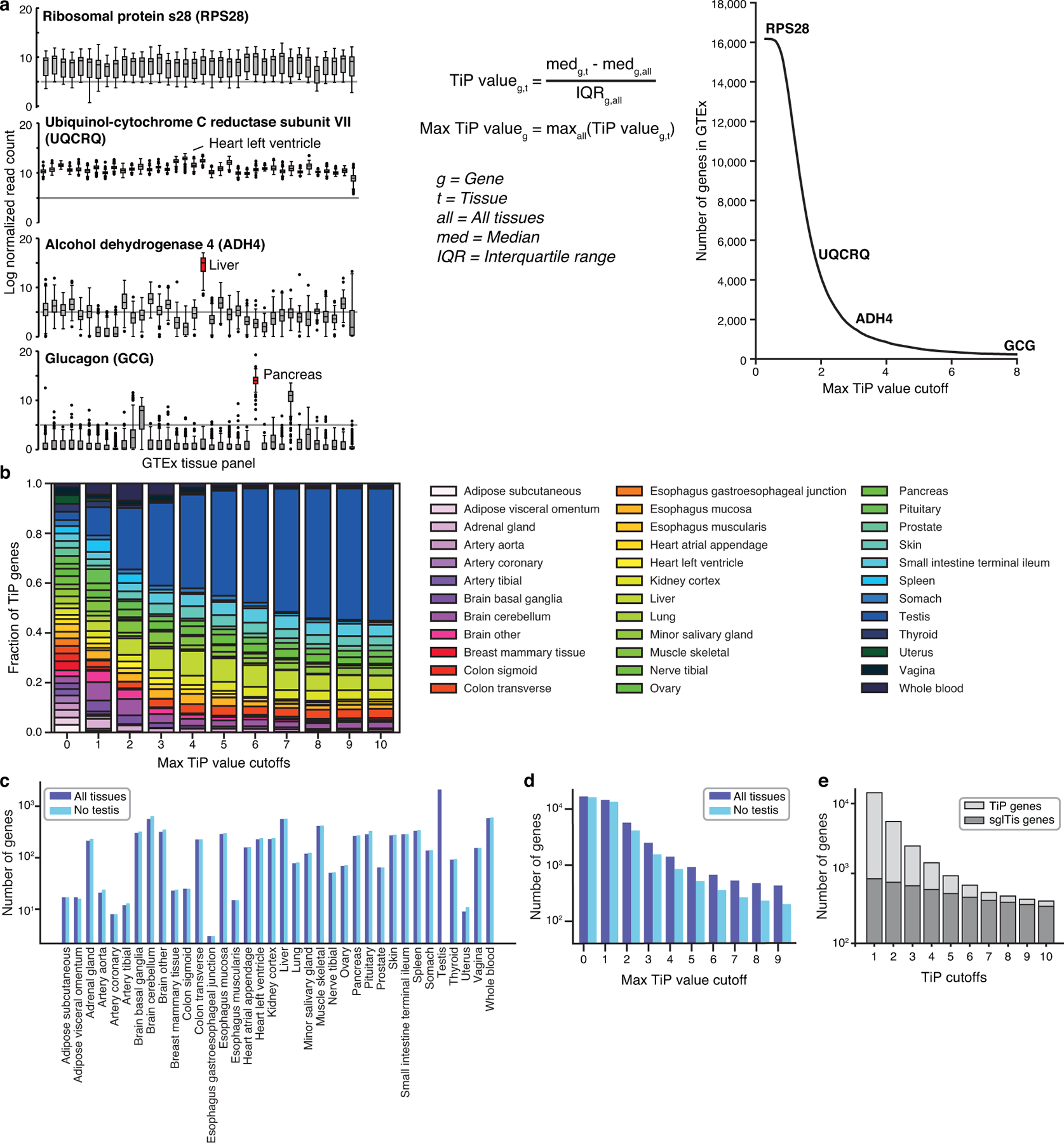
Despite recent advances in systematic genome-wide identification of tissue-preferentially expressed (TiP) genes4 (Extended Data Fig. 7, Supplementary Table 22), we lack a concrete understanding of how the surprisingly small set of TiP genes operate together and coordinate their activity with the core ‘housekeeping’ machinery to mediate tissue-specific functions. Insights can be obtained from investigation of the tissue-specific network context of TiP proteins, inferred from integrating protein interactome data with tissue transcriptomes (Supplementary Table 23). However, we should not expect uniform coverage of TiP proteins with PPIs using experimental methods that demand expression of both partners within a single immortalized cell line or result from screening an incomplete ORFeome. Indeed, contrary to protein complex11–13 and literature-curated interactome maps38 as well as our previously published binary PPI datasets2,14, we find that TiP proteins are well-represented in HuRI (Fig. 5a, Extended Data Fig. 8a).
Fig. 5 |. Tissue-specific functions are largely mediated by interactions between TiP proteins and uniformly expressed proteins.
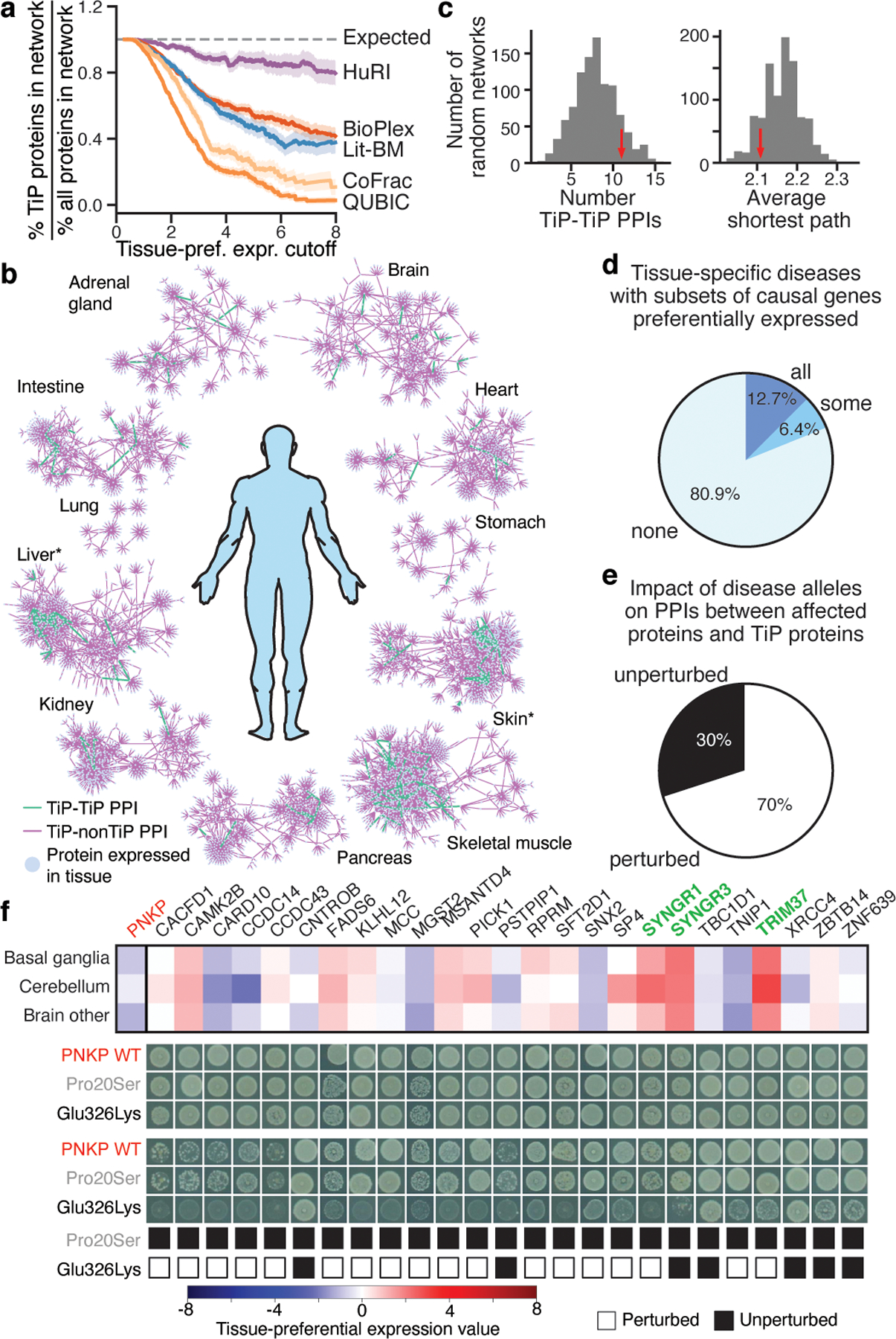
a, Tissue-preferentially expressed (TiP) protein coverage by PPI networks for increasing levels of tissue-preferential expression (shaded error bands proportional to standard error on proportion, n ≥ 233 genes). b, Tissue-preferential sub-networks. *P < 0.001, 1-sided empirical test for TiP proteins being close to each other (n = 19,960–30,217 PPIs per subnetwork). c, Empirical test of closeness of TiP proteins in the brain sub-network, 1,000 random networks. d, Tissue-specific diseases split by tissue-preferential expression levels of causal genes. e, Tested tissue-specific diseases split by PPI perturbation result. f, Expression profile of PNKP and interactors in brain tissues and PPI perturbation pattern of disease causing (Glu326Lys) and benign (Pro20Ser) mutation. Yeast growth phenotypes on SC-Leu-Trp (upper) or SC-Leu-Trp-His+3AT (3-Amino-1,2,4-triazole) media (lower). Green gene symbols: preferentially expressed. Only interactors expressed in brain shown.
Restricting HuRI to PPIs between proteins expressed in the same tissue, we observe that TiP proteins engage in as many PPIs and are as central as more uniformly expressed proteins (Extended Data Fig. 8b), contrary to previous observations using literature-curated PPI networks39,40. This result, paired with the fact that PPIs mediated by a TiP protein are effectively also tissue-specific, leads to the finding that the fraction of tissue-specific PPIs in the protein interactome as characterized by HuRI is higher than that of tissue-specific genes in the expressed genome, indicating that substantial information on tissue-specific functions can only be obtained from the interactome. The opposite is observed for Lit-BM, likely owing to its bias against TiP genes (Extended Data Fig. 8c).
To investigate the local network neighborhoods of TiP proteins within their respective tissue contexts, we used HuRI to derive protein interactome maps for 35 tissues4,41, each of which contains about 25,000 PPIs (Supplementary Table 24, Extended Data Fig. 8d). Within each tissue PPI network, we focused on the interactions involving at least one TiP protein (Fig. 5b). The TiP PPI networks show extensive interactions between TiP and non-TiP proteins, but with few TiP-TiP PPIs. Despite significant enrichments for HuRI to link proteins that work in the same biological process, TiP-TiP PPIs, as highlighted for brain in Fig. 5c, are not enriched, nor is the average shortest path among TiP proteins shorter than in degree-controlled randomized networks (P > 0.05, empirical test). Using either metric, TiP proteins were found to be significantly close to each other in only six of 35 tissues. In four of these six tissues, enrichment for network proximity was driven by clusters of specifically expressed keratins or late-cornified envelope proteins (Extended Data Fig. 8e). These results support a model in which tissue-specific functions emerge through interactions between TiP proteins and more uniformly expressed members of the basic cellular machinery, presumably modulating and adapting common cellular processes for cellular context-specific needs42.
One biological process with both cell-type and developmental stage-specific homeostatic roles is apoptosis. We used HuRI to identify proteins with interaction partners that were enriched for known apoptosis regulators (Supplementary Table 25). Five proteins among the top ten predictions had previously demonstrated roles in apoptosis (Supplementary Note 3). Among three TiP genes predicted to be implicated in apoptosis (Extended Data Fig. 8f, g), we further examined OTUD6A. Abundance of OTUD6A negatively correlated with time-of-death after addition of TRAIL (TNF-related apoptosis-inducing ligand; P = 0.012, two-sided, empirical test, n = 40 cells), but not after expression of OTUD6A alone (Extended Data Fig. 8h, Supplementary Table 26), suggesting that OTUD6A participates in the apoptosis pathway but is not an inducer of cell death. This and other evidence (Extended Data Fig. 8f, i, Supplementary Note 3) suggests that OTUD6A exerts an apoptosis sensitization function via transcriptional activation in a haematopoietic cellular context.
Mechanisms of tissue-specific diseases
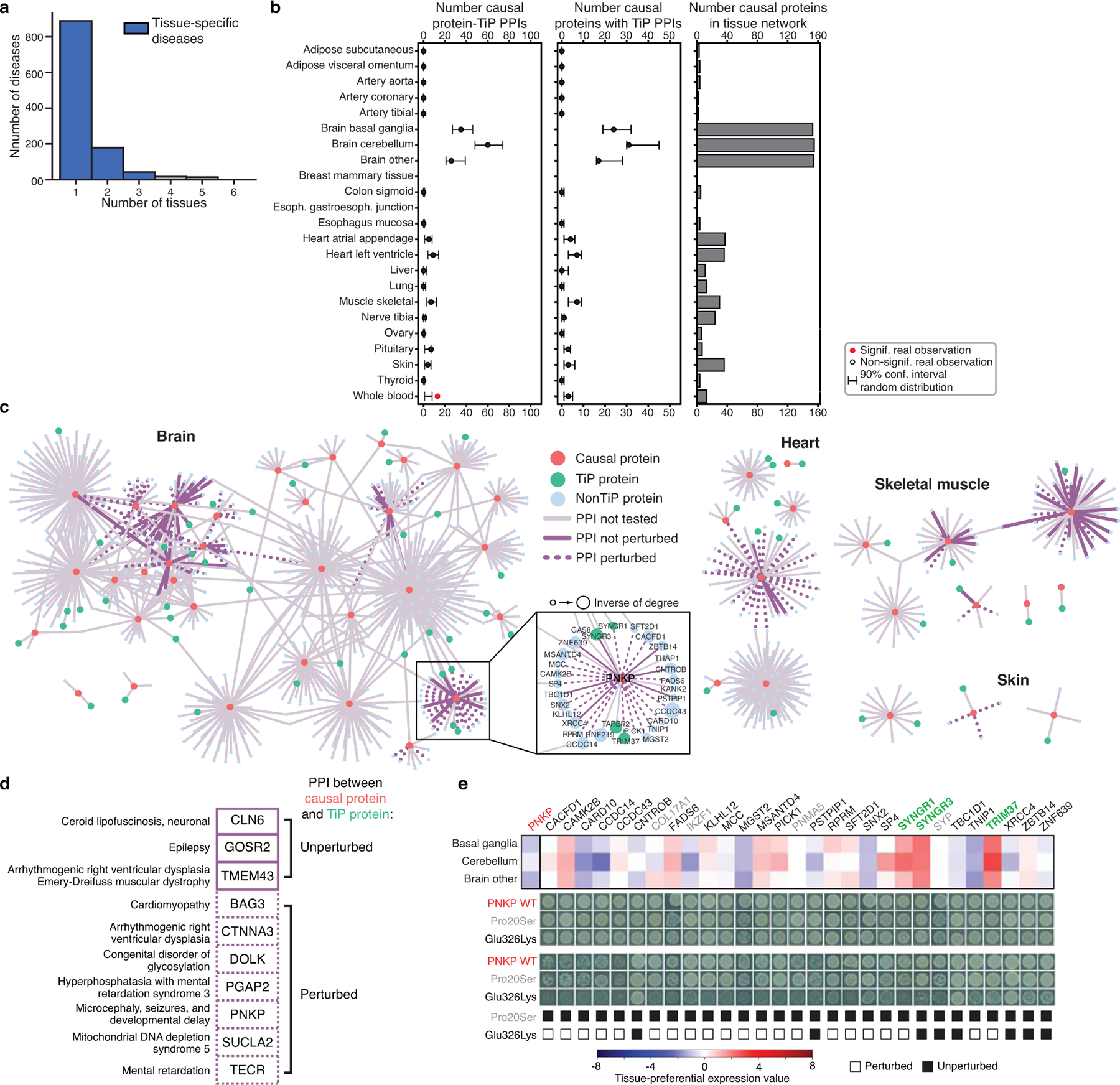
Many Mendelian diseases display tissue-specific phenotypes, rarely explained by tissue-specific expression of genes with disease-associated mutations43 (Fig. 5d, Extended Data Fig. 9a). Such mutations broadly or specifically affect PPIs involving the mutated protein44. Perturbations of PPIs between uniformly expressed disease-associated proteins and TiP proteins in the affected tissues have been suggested to underlie the tissue-specific phenotypes of those diseases43. In HuRI-derived tissue PPI networks, we find 130 such PPIs involving 63 distinct non-TiP disease-causal proteins and 94 TiP proteins. Although we see no enrichment for PPIs between causal proteins and TiP proteins (Extended Data Fig. 9b, Supplementary Note 4), this does not rule out the possibility that perturbations of some of these interactions mediate tissue-specific phenotypes of Mendelian diseases.
To explore this hypothesis, we experimentally tested whether pathogenic variants associated with Mendelian diseases were able to perturb these PPIs. Of ten causal proteins tested, seven showed perturbation of PPIs to preferentially expressed interaction partners in the corresponding “disease tissues” (Fig 5e, Extended Data Fig. 9c, d, Supplementary Table 27, 28). One example is PNKP (polynucleotide kinase 3’-phosphatase) whose mutations have been associated with microcephaly, seizures, and developmental delay. The pathogenic PNKP mutation Glu326Lys affects neither the DNA kinase nor DNA phosphatase activity of PNKP, rendering the mechanism of pathogenicity unclear45. We observed that Glu326Lys perturbed PPIs with two partners preferentially expressed in the brain, SYNGR1 and TRIM37, whereas a benign control mutation Pro20Ser46 did not affect any PNKP PPIs (Fig. 5f, Extended Data Fig. 9c, e). TRIM37 facilitates DNA repair47, suggesting a potential mechanism by which perturbation of this interaction could affect the brain-specific DNA repair function of PNKP. In other examples, HuRI identified CTNNA3 and SUCLA2 to have respective TiP interaction partners TRIM54 and ARL6IP1 (Extended Data Fig. 10), which cause similar diseases with overlapping symptoms48,49, supporting the relevance of these interactions in the physiopathology. Overall, this study yields hypotheses of molecular mechanisms for otherwise unexplained tissue-specific phenotypes of seven Mendelian diseases (Extended Data Fig. 9d) and demonstrates the utility of HuRI as a reference to study biological mechanisms within specific disease contexts.
Discussion
Here, we present HuRI, a systematically generated human protein interactome map with more than 50,000 PPIs of high biophysical quality. While HuRI displays highly significant overlap with known functional relationships, the cellular function of most individual PPIs remains to be elucidated. We show that follow-up studies on the function of proteins and PPIs can be guided by integration of HuRI with contextual genome, transcriptome and proteome data to infer the cellular context in which subnetworks of PPIs operate together to mediate a function. With advances in single cell transcriptomics8 as well as systematic determination of subcellular protein localization, inference of functional PPI subnetworks that are specific for a given cellular state will further increase in precision. However, a priori removal of PPIs from HuRI because they are not currently known to function together in a physiological cellular context could discard data that can help, e.g., to understand the functional consequences of dysregulated gene and protein expression causing disease.
Despite our extensive screening, many PPIs remained undetected as Y2H, like all characterized assays15,16,18, has limited sensitivity, detecting no interactions for half of the tested proteins. This negative result can guide the design of future interactome mapping efforts to target these proteins. Due to the limitations of Y2H, we expect HuRI to be depleted for PPIs that depend on post-translational processing of human proteins that the yeast cell is unable to catalyze or that require additional partners to stabilize the interaction. Screening only one isoform per gene also misses interaction partners specific to alternative spliceforms50. Accurate estimation of the total size of the interactome remains challenging. PPIs display a continuum of binding strength or stability that, along with other factors, could underlie a continuum of detectability, as this study suggests. Furthermore, the results obtained by us and others12 indicate that very stable and functionally conserved PPIs constitute a minority of the interactome.
While incomplete, HuRI’s proteome and interactome coverage and uniformity enable its use as a reference for the study of most aspects of human cellular function. Efforts to further complete this reference will require development of new technologies as well as integration with complementary reference maps of protein complex assemblies13. Although multiple challenges remain to be solved for a complete and context-specific map of protein functions, interactions, and higher-level organization, HuRI provides an unbiased genome-scale scaffold with which to coordinate this information as it emerges.
Extended Data
Extended Data Fig. 1 |. Y2H assay development and validation of HuRI.
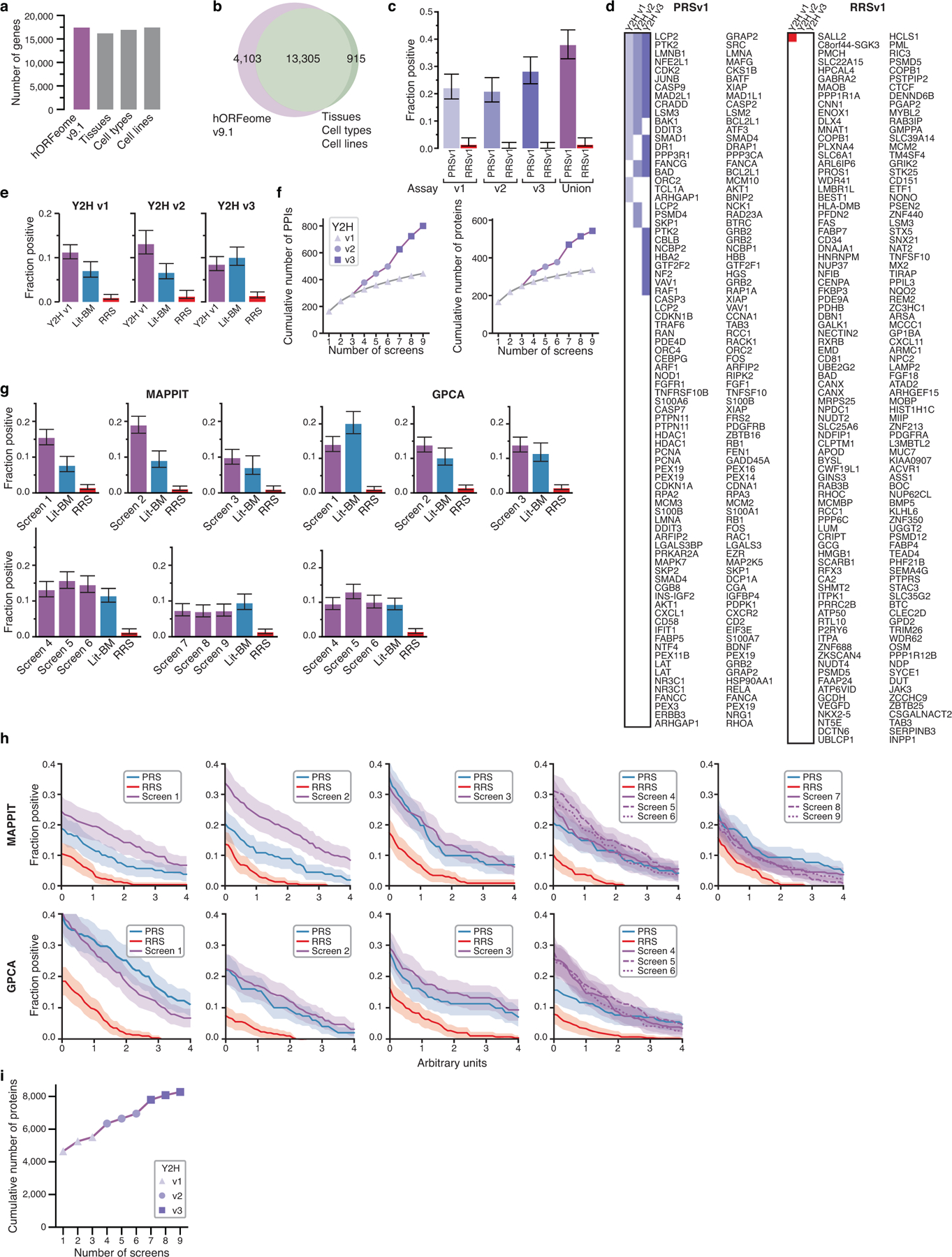
a, Number of protein-coding genes in hORFeome v9.1 and GTEx, FANTOM, and HPA transcriptome projects. The number of genes in hORFeome v9.1 is on par with the number of genes found to be expressed in three comprehensive individual transcriptome sequencing studies and includes 94% of the genes with robust evidence of expression in all three. b, Overlap between hORFeome v9.1 and intersection of transcriptomes in a. c, Individual and combined recovery of PRSv1 and RRSv1 pairs by Y2H assay versions (n = 252, 270). d, Colored squares showing which protein pairs were detected in PRSv1 (left) and RRSv1 (right) by Y2H assay versions. e, Recovery rates of Lit-BM and PPIs from screens of a 2k-by-2k gene test space per Y2H assay version in MAPPIT. f, Cumulative PPI count performing three screens with each Y2H assay version in the test space compared to nine screens with Y2H assay version 1. g, h, MAPPIT and GPCA recovery of Lit-BM and PPIs from screens of Space III when split by screen at a RRS rate of 1% (g) or across a range of thresholds (h). All error bars, in c, e, g, are 68.3% Bayesian confidence interval, shaded error band in h is standard error of proportion and n = between 101 and 395 pairs successfully tested for each category. i, Number of proteins in HuRI, detected with each additional screen.
Extended Data Fig. 2 |. Definition of literature-curated PPI datasets.
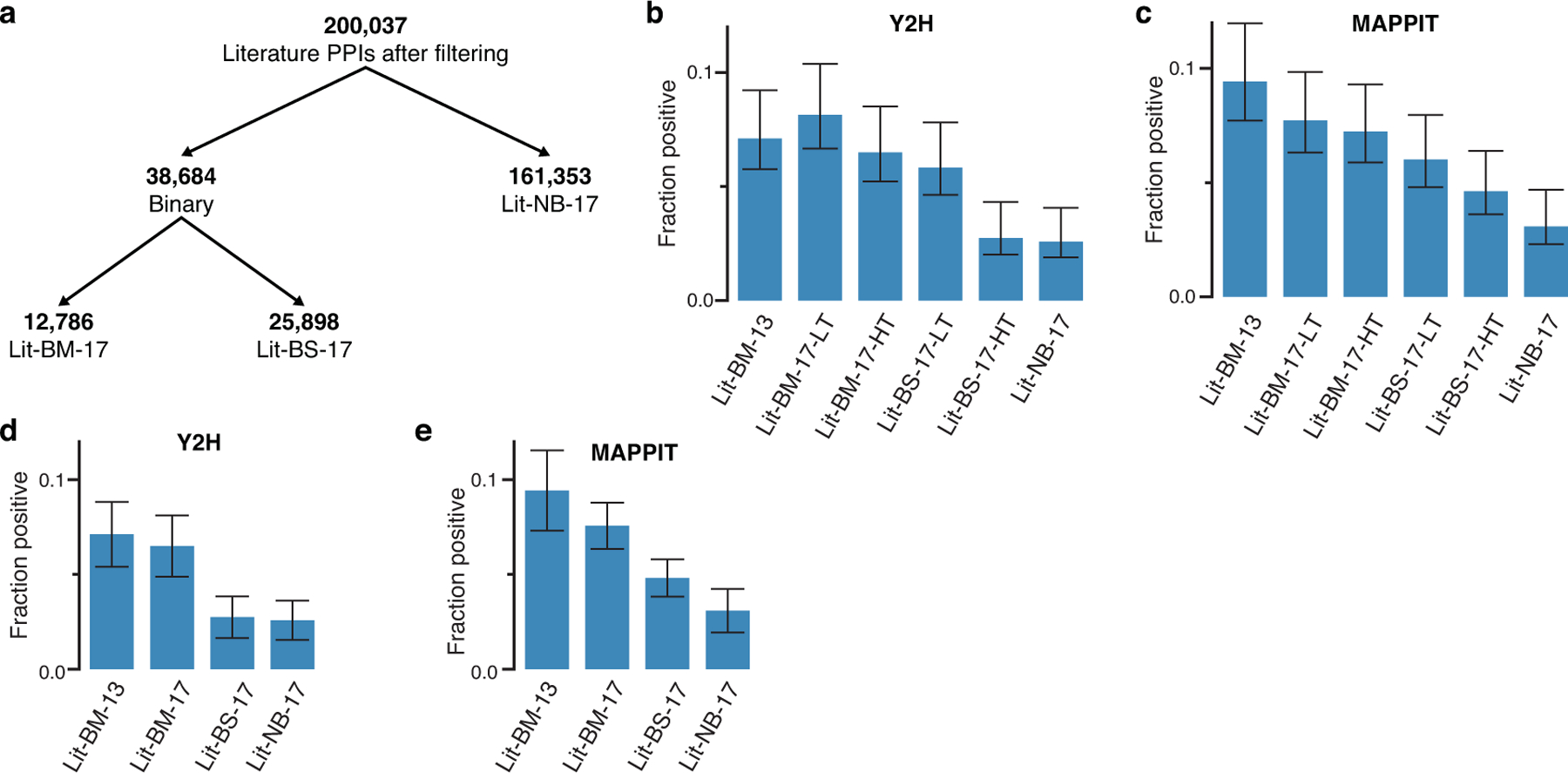
a, Categorization of literature-curated PPIs into distinct subsets based on the experimental methods in which they were detected and the number of pieces of experimental evidence. b-e, Results of testing the different categories of literature-curated pairs in Y2H (b, d) and MAPPIT (c, e) where the pairs have been further divided into HT - high throughput and LT - low throughput subsets (b, c). BM: binary multiple; BS: binary singleton; NB: non-binary. Between n = 191–471 successfully tested PPIs for each category.
Extended Data Fig. 3 |. Stericity and interaction strength contribute to PPI detectability.
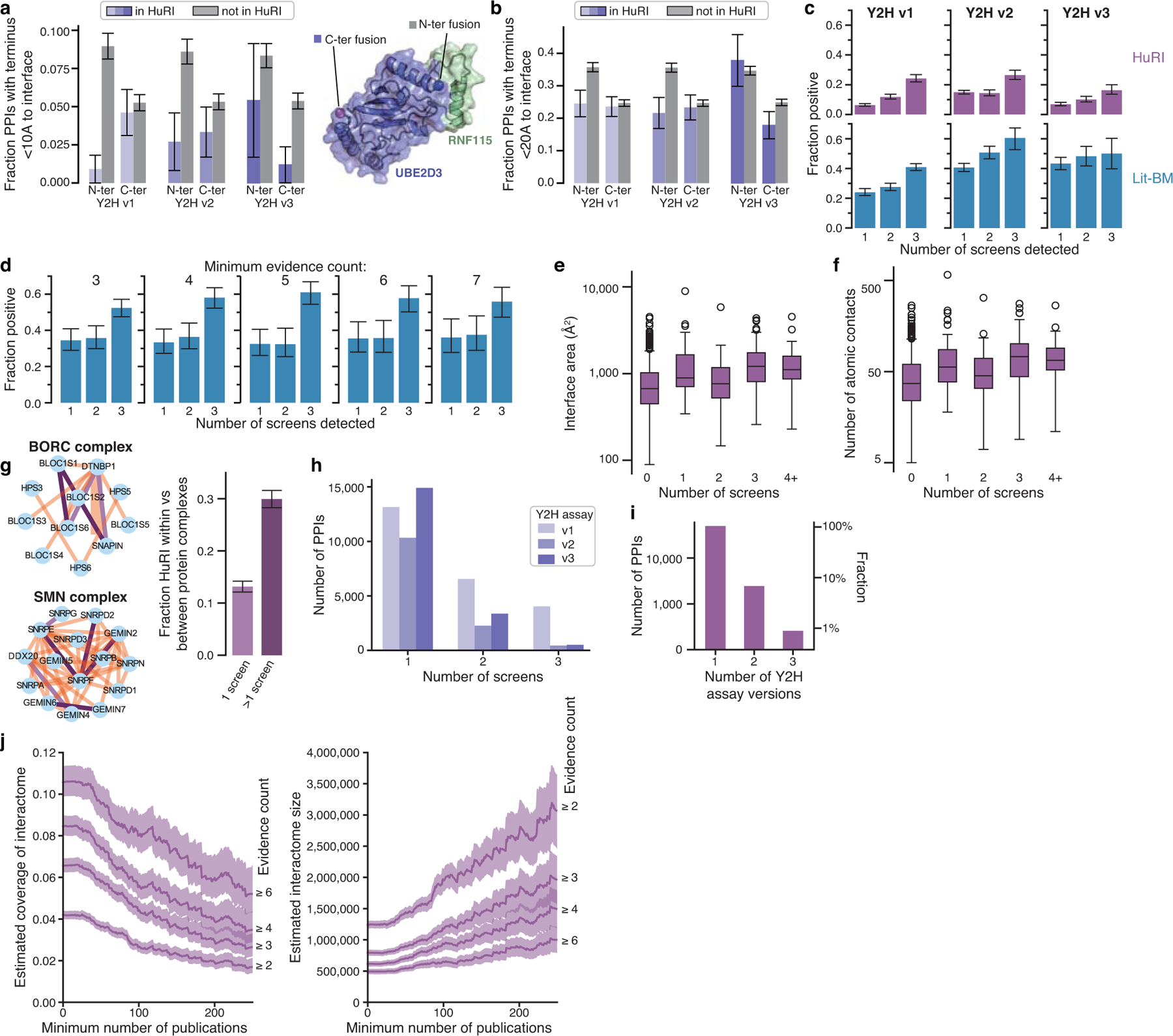
a, b, Fraction of PPIs with N or C-terminus < 10 Å (a) or 20 Å (b) to PPI interface, for PPIs with known structure in and not in HuRI (n = 37–1,891 PPIs). Error bars are standard error of proportion. The structure of UBE2D3 bound to RNF115 illustrates an example of a PPI found only by Y2H assay version 3 (PDB code: 5ulh). c, MAPPIT recovery rates of HuRI and Lit-BM PPIs that were also detected in HuRI by the number of screens each pair was detected in. Error bars are 68.3% Bayesian confidence interval (n = 22–793 PPIs successfully tested in each category). d, MAPPIT recovery rates of Lit-BM PPIs that were also detected in HuRI, for increasing number of pieces of experimental evidence per PPI. Error bars are 68.3% Bayesian confidence interval (n = 24–61 PPIs successfully tested in each category). e-f, Distributions of interaction interface area (e) or number of atomic contacts (f) by the number of HuRI screens in which a PPI is detected, with boxplots showing median, interquartile range (IQR), and 1.5 × IQR (with outliers), n = 1004 PPIs. g, Examples of within-complex interactions detected in HuRI (purple) and BioPlex (orange). Fraction of HuRI PPIs between proteins of protein complexes that link proteins of the same complex, split by PPIs found in single and multiple screens (dark purple). Error bars are standard error of proportion, n = 1,042 and 775 PPIs. h, Number of screens each PPI in HuRI was detected in, split by Y2H assay version. i, Number of Y2H assay versions each PPI in HuRI was detected in. j, Estimates of the size of the total binary protein interactome and the fraction covered by HuRI, as a function of the minimum number of publications per gene and the minimum number of evidence for the Lit-BM reference. Error bands are 68.3% Bayesian confidence interval, n ≥ 170 Lit-BM PPIs.
Extended Data Fig. 4 |. HuRI provides direct contact information for proteins in complexes.

Intra-complex PPIs are shown for protein complexes from CORUM as found in BioPlex (orange) or HuRI (purple). HuRI PPIs are further distinguished into PPIs found in single (light purple) or multiple screens (dark purple).
Extended Data Fig. 5 |. Topological and functional significance of HuRI.
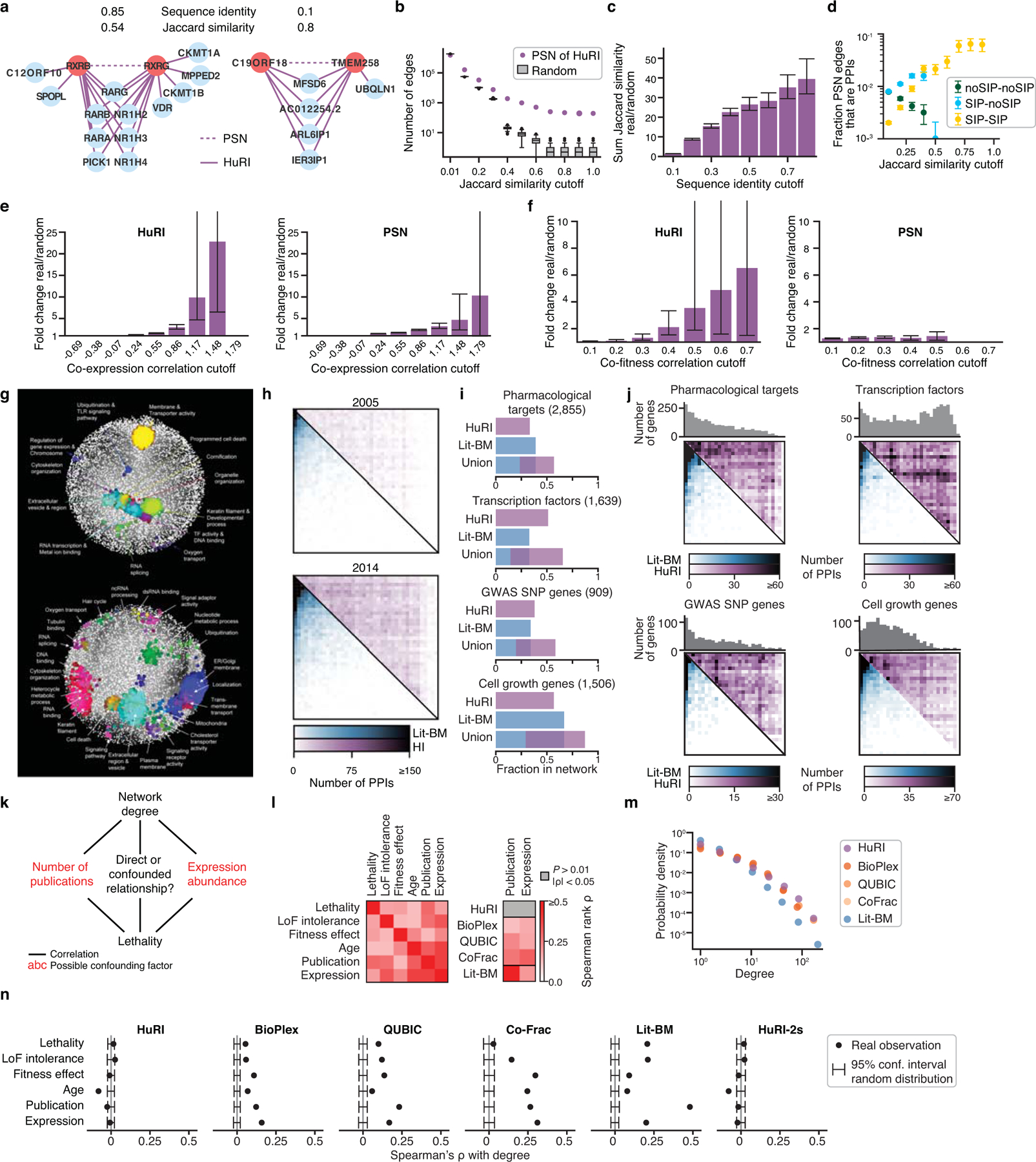
a, Examples of protein pairs in HuRI with high interaction profile similarity and both high (left) and low sequence identity (right). b, The number of pairs of proteins in HuRI and 100 random networks at increasing Jaccard similarity cutoffs, with boxplots showing median, interquartile range (IQR), and 1.5 × IQR (with outliers). PSN: profile similarity network. c, Enrichment over random networks of the sum of Jaccard similarities of pairs of proteins in HuRI above at increasing thresholds of sequence identity. Error bars are 95% confidence intervals, center is relative to mean of random networks. d, Fraction of PSN edges that are also PPIs in HuRI, split by the PPIs involving no, one or two self-interacting proteins (SIPs), at increasing Jaccard similarity cutoffs. Error bars are standard error of proportion. e, f, Enrichment over random networks of the PPI count (left) or sum of Jaccard similarities (right) of HuRI PPIs or PSN pairs, respectively, at increasing co-expression (e) and co-fitness (f) cutoffs. Error bars are 95% confidence interval, center is relative to mean of random networks. g, Functional modules in HuRI (top) and its PSN (bottom) with functional annotations. h, Heatmaps of PPI counts, ordered by number of publications, for our previous human interactome maps and Lit-BM i, j, Fraction of genes with at least one PPI for biomedically interesting genes. Heatmap of HuRI and Lit-BM PPI counts between proteins, ordered by number of publications, restricted to PPIs involving genes from the corresponding gene set. k, Schematic of relation between variables: observed PPI degree, abundance, study bias and lethality. l, Correlation matrices. LoF: Loss-of-Function. PPI datasets refer to their network degree. m, Degree distribution of various PPI networks, together. n, Empirical determination of significance of correlation between various network degrees and gene properties. HuRI-2s = subset of HuRI found in at least two screens, (n = 13,441–53,704 PPIs per network).
Extended Data Fig. 6 |. Incomplete protein localization annotation likely underlies apparent lack of co-localization of proteins interacting in HuRI.
a, Odds ratios of proteins in different subcellular compartments and PPI datasets. n = 125–3,941 proteins per compartment, two-tailed Fisher’s exact test. b, The subnetwork of HuRI involving extracellular vesicle (EV) proteins. Names of high-degree proteins are shown. c, Number of PPIs in HuRI between EV proteins compared to the distribution from randomized networks (grey). d, Western Blot of SDCBP (left panel) and ACTB (loading control, right panel) in wild-type (WT) and three knockout (KO) cell lines (#7-#9), repeated twice in two independent laboratories. Full scanned image was displayed, obtained by ChemiDoc MP imager (Bio-Rad, Hercules, CA). Cell line #8 was used for EV proteomics. e, Fraction of proteins whose abundance in EVs was significantly reduced in the SDCBP KO cell line, split by proteins interacting and not interacting with SDCBP as identified in HuRI. Error bars are standard error of proportion (n = 6 interactors, 638 non-interactors, *p = 0.042, one-tailed empirical test). f, Schematic illustrating that the number of HuRI PPIs between proteins from two different compartments should correlate with the enrichment of both compartment pairs to overlap, if co-localization annotation is incomplete. g, Scatter plot showing, for each pair of subcellular compartments, odds ratios quantifying the enrichment for proteins located in both compartments versus the enrichment of the density of PPIs between proteins located to either compartment. Size of points is scaled by the standard error of the x axis variable. Regression line and 95% confidence interval are shown. h, The z-score of the regression slope of g compared to those of random networks.
Extended Data Fig. 7 |. Investigation of tissue-preferential expression data.
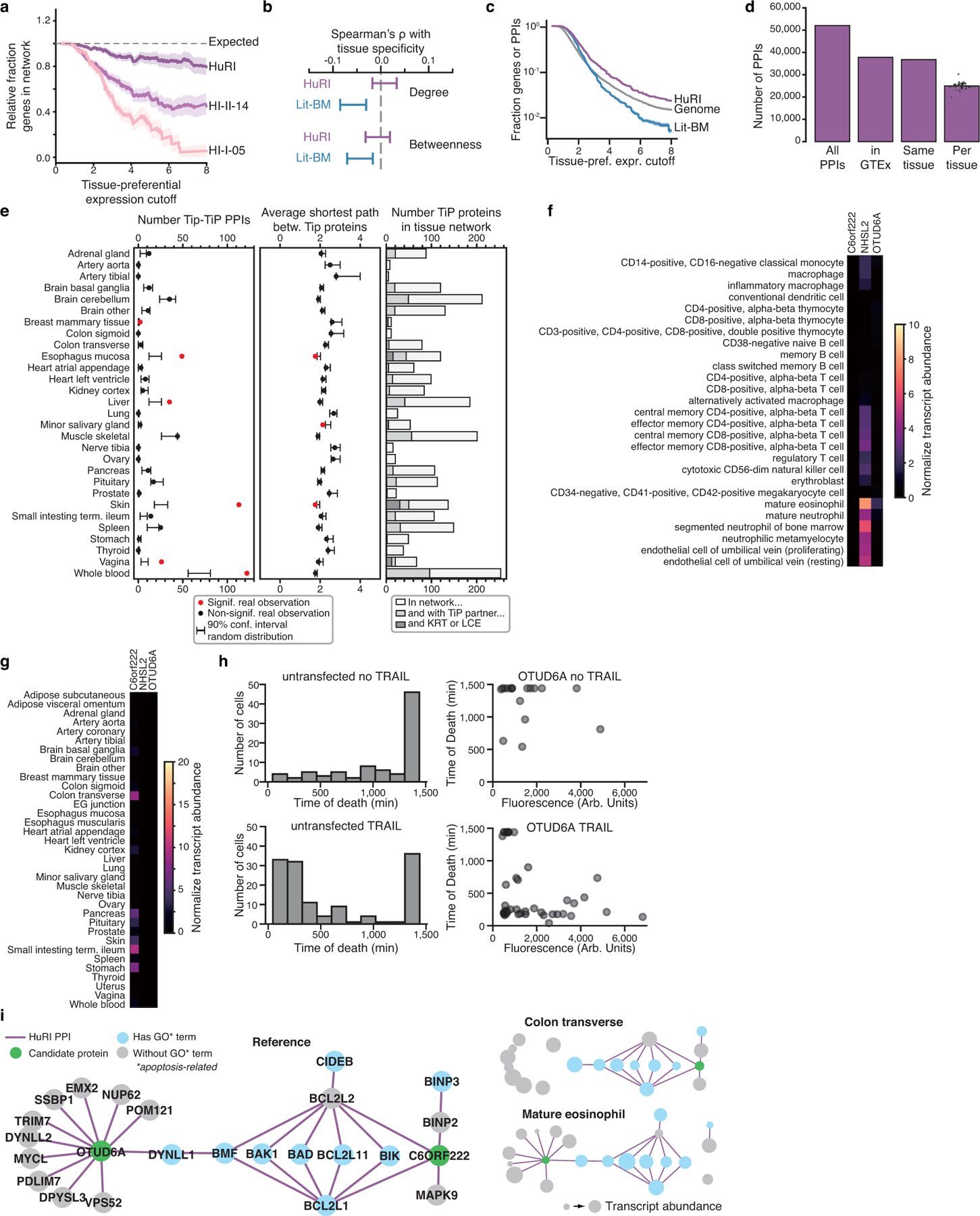
a, Examples of genes displaying different levels of tissue-preferential (TiP) expression across the GTEx tissue panel (left), with boxplots showing median, interquartile range (IQR), and 1.5 × IQR (with outliers), n = 90–779 samples per tissue. Equation to calculate tissue-preferential expression for every gene-tissue pair and the maximum TiP value for every gene (middle). Number of genes showing tissue-preferential expression for increasing tissue-preferential expression cutoffs (right). b, Relative number of TiP genes for every tissue for increasing tissue-preferential expression cutoffs. c-d, Differences in number of TiP genes upon removal of testis prior to TiP value calculation per tissue (TiP value cutoff = 2) (c) and in total for increasing tissue-preferential expression cutoffs (d). e, Number of TiP genes and number of TiP genes that are also exclusively expressed in one tissue (sglTis: single tissue) for increasing tissue-preferential expression cutoffs.
Extended Data Fig. 8 |. PPIs between TiP proteins and uniformly expressed proteins likely adapt basic cellular processes to mediate cellular context-specific functions.
a, TiP protein coverage by CCSB PPI networks for increasing levels of tissue-preferential expression, (shaded error bands proportional to standard error on proportion, n ≥ 233 genes). b, Spearman correlation coefficients and 95% confidence intervals for correlations between degree or betweenness and tissue specificity for HuRI and Lit-BM (n = 6,684 and 4,971 proteins). c, Fraction of HuRI and Lit-BM that involve TiP proteins compared to fraction of genome that are TiP genes for increasing levels of tissue-preferential expression. d, Number of PPIs in HuRI, involving proteins in GTEx, where both proteins are expressed in the same tissue, and the mean of the tissue-specific subnetworks where error bar is standard deviation. e, Test for enrichment of TiP-TiP PPIs (left) and significance of average shortest path between TiP proteins (middle) in each tissue subnetwork, number of TiP proteins in each subnetwork, interacting with other TiP proteins, being part of Keratin (KRT) or Late-cornified envelope (LCE) protein family (right). f, g, Transcript expression levels across the BLUEPRINT hematopoietic cell lineage (f) and GTEx tissue panel (g) for three candidate genes predicted to function in apoptosis. EG = esophagus gastroesophageal. h, Histogram of number of untransfected cells and their time of death (left) without (top) and with (bottom) addition of TRAIL. Time of death of cells expressing OTUD6A-GFP fusions versus OTUD6A expression measured as fluorescence (right) without (top) and with (bottom) addition of TRAIL. i, Apoptosis-related network context of OTUD6A and C6ORF222 in HuRI, unfiltered (left) and filtered using colon transverse or mature eosinophil transcript levels (right).
Extended Data Fig. 9 |. Potential mechanisms of tissue-specific diseases.
a, Histogram of the number of Mendelian diseases showing symptoms in a number of tissues. b, Test for enrichment of causal proteins associated with tissue-specific Mendelian diseases to interact with TiP proteins of affected tissues. c, Network neighborhood of uniformly expressed causal proteins of tissue-specific diseases found to interact with TiP proteins in HuRI, indicating PPI perturbation by mutations. d, Causal genes split by mutation found to perturb PPI to TiP protein (dashed) or not (solid). e, Expression profile of PNKP and interactors in brain tissues and PPI perturbation pattern of disease causing (Glu326Lys) and benign (Pro20Ser) mutation. Yeast growth phenotypes on SC-Leu-Trp (upper) or SC-Leu-Trp-His+3AT media (lower) are shown; green/grey gene symbols: preferentially/not expressed.
Extended Data Fig. 10 |. Mutations in uniformly expressed causal proteins associated with tissue-specific Mendelian diseases perturb interactions to TiP proteins.

Expression profile and interaction perturbation profile of nine causal proteins and their interaction partners. Affected tissues were selected for display (top). Control of AD and DB (Gal 4 DNA binding domain) plasmid presence and cell density by spotting yeast colonies on SC-Leu-Trp media (upper). Detection of PPIs by spotting yeast on SC-Leu-Trp-His+3AT media (lower), where yeast growth indicates PPIs. WT = wild-type, red letters = causal proteins or alleles, grey gene symbols = interaction partners not expressed in affected tissues, grey alleles = not pathogenic, green gene symbols = TiP interaction partners in affected tissues.
Supplementary Material
Acknowledgements
This paper is dedicated to the memory of Dr. Deborah Allinger. We thank Pablo Porras Millan and the IntAct team for their help in disseminating our PPI data via IntAct, pre- and post-publication. We thank Ulrich Braunschweig, Jonathan Ellis, and Benjamin J. Blencowe for help with data analysis. We also thank Qian Zhu and Olga G. Troyanskaya as well as Joshua Pan and Cigall Kadoch for sharing co-expression and co-fitness data, respectively. We thank Katharine S. Tuttle for help with graphics. This work was primarily supported by the National Institute of Health (NIH) National Human Genome Research Institute (NHGRI) grant U41HG001715 (M.V., F.P.R., D.E.H., M.A.C., G.D.B. and J.T.) with additional support from NIH grants P50HG004233 (M.V. and F.P.R.), U01HL098166 (M.V.), U01HG007690 (M.V.), R01GM109199 (M.A.C.), Canadian Institute for Health Research (CIHR) Foundation Grants (F.P.R. and J.Rak.), the Canada Excellence Research Chairs Program (F.P.R.) and an American Heart Association grant 15CVGPS23430000 (M.V.). D.-K.K. was supported by a Banting Postdoctoral Fellowship through the Natural Sciences and Engineering Research Council (NSERC) of Canada and by the Basic Science Research Program through the National Research Foundation (NRF) of Korea funded by the Ministry of Education (2017R1A6A3A03004385). C.Pon. was supported by a Ramon Cajal fellowship (RYC-2017-22959). G.M.S. was supported by NIH Training Grant T32CA009361. M.V. is a Chercheur Qualifié Honoraire from the Fonds de la Recherche Scientifique (FRS-FNRS, Wallonia-Brussels Federation, Belgium).
Footnotes
Competing interests J.C.M. is a founder and CEO of seqWell, Inc; F.P.R. and M.V. are shareholders and scientific advisors of seqWell, Inc.
Extended data is linked to the online version of the paper.
Supplementary information is linked to the online version of the paper.
Online content
Methods, supplementary notes, additional references, and supplementary tables are available online. Detailed sample size information for each figure panel is provided in Supplementary Table 29.
Data availability
HuRI, Lit-BM, and all previously published human interactome maps from CCSB are available at http://interactome-atlas.org. The PPI data from this publication is also available through IntAct (https://www.ebi.ac.uk/intact/) with the identifier IM-25472. All HuRI-related networks from this study are available at NDExbio.org (https://tinyurl.com/networks-HuRI-paper). The raw and analyzed proteomic data were deposited in the PRIDE repository (https://www.ebi.ac.uk/pride/) with the accession number PXD012321.
Code availability
Analysis code is available at github.com/CCSB-DFCI/HuRI_paper
- 1.Vidal M, Cusick ME & Barabási A-L Interactome networks and human disease. Cell 144, 986–998 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Rolland T et al. A proteome-scale map of the human interactome network. Cell 159, 1212–1226 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Amberger JS, Bocchini CA, Schiettecatte F, Scott AF & Hamosh A OMIM.org: Online Mendelian Inheritance in Man (OMIM®), an online catalog of human genes and genetic disorders. Nucleic Acids Res. 43, D789–798 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Melé M et al. The human transcriptome across tissues and individuals. Science 348, 660–665 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Thul PJ et al. A subcellular map of the human proteome. Science 356, eaal3321 (2017). [DOI] [PubMed] [Google Scholar]
- 6.Lek M et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature 536, 285–291 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.FANTOM Consortium and the RIKEN PMI and CLST (DGT) et al. A promoter-level mammalian expression atlas. Nature 507, 462–470 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Regev A et al. The human cell atlas. eLife 6, e27041 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lander ES et al. Initial sequencing and analysis of the human genome. Nature 409, 860–921 (2001). [DOI] [PubMed] [Google Scholar]
- 10.Venter JC et al. The sequence of the human genome. Science 291, 1304–1351 (2001). [DOI] [PubMed] [Google Scholar]
- 11.Wan C et al. Panorama of ancient metazoan macromolecular complexes. Nature 525, 339–344 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Hein MY et al. A human interactome in three quantitative dimensions organized by stoichiometries and abundances. Cell 163, 712–723 (2015). [DOI] [PubMed] [Google Scholar]
- 13.Huttlin EL et al. Architecture of the human interactome defines protein communities and disease networks. Nature 545, 505–509 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Rual J-F et al. Towards a proteome-scale map of the human protein-protein interaction network. Nature 437, 1173–1178 (2005). [DOI] [PubMed] [Google Scholar]
- 15.Braun P et al. An experimentally derived confidence score for binary protein-protein interactions. Nat. Methods 6, 91–97 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Venkatesan K et al. An empirical framework for binary interactome mapping. Nat. Methods 6, 83–90 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Chen Y-C, Rajagopala SV, Stellberger T & Uetz P Exhaustive benchmarking of the yeast two-hybrid system. Nat. Methods 7, 667–668 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Choi SG et al. Maximizing binary interactome mapping with a minimal number of assays. Nat. Commun 10, 3907 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Eyckerman S et al. Design and application of a cytokine-receptor-based interaction trap. Nat. Cell Biol 3, 1114–1119 (2001). [DOI] [PubMed] [Google Scholar]
- 20.Cassonnet P et al. Benchmarking a luciferase complementation assay for detecting protein complexes. Nat. Methods 8, 990–992 (2011). [DOI] [PubMed] [Google Scholar]
- 21.Mosca R, Céol A & Aloy P Interactome3D: adding structural details to protein networks. Nat. Methods 10, 47–53 (2013). [DOI] [PubMed] [Google Scholar]
- 22.Tompa P, Davey NE, Gibson TJ & Babu MM A million peptide motifs for the molecular biologist. Mol. Cell 55, 161–169 (2014). [DOI] [PubMed] [Google Scholar]
- 23.Sambourg L & Thierry-Mieg N New insights into protein-protein interaction data lead to increased estimates of the S. cerevisiae interactome size. BMC Bioinformatics 11, 605 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Leid M et al. Purification, cloning, and RXR identity of the HeLa cell factor with which RAR or TR heterodimerizes to bind target sequences efficiently. Cell 68, 377–395 (1992). [DOI] [PubMed] [Google Scholar]
- 25.Willy PJ et al. LXR, a nuclear receptor that defines a distinct retinoid response pathway. Genes Dev. 9, 1033–1045 (1995). [DOI] [PubMed] [Google Scholar]
- 26.Kovács IA et al. Network-based prediction of protein interactions. Nat. Commun 10, 1240 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Baryshnikova A Systematic functional annotation and visualization of biological networks. Cell Syst. 2, 412–421 (2016). [DOI] [PubMed] [Google Scholar]
- 28.Graham DB et al. TMEM258 is a component of the oligosaccharyltransferase complex controlling ER stress and intestinal inflammation. Cell Rep. 17, 2955–2965 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Yamamoto Y, Yoshida A, Miyazaki N, Iwasaki K & Sakisaka T Arl6IP1 has the ability to shape the mammalian ER membrane in a reticulon-like fashion. Biochem. J 458, 69–79 (2014). [DOI] [PubMed] [Google Scholar]
- 30.Abdel-Salam GMH et al. A homozygous IER3IP1 mutation causes microcephaly with simplified gyral pattern, epilepsy, and permanent neonatal diabetes syndrome (MEDS). Am. J. Med. Genet. Part A 158A, 2788–2796 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Jeong H, Mason SP, Barabási A-L & Oltvai ZN Lethality and centrality in protein networks. Nature 411, 41–42 (2001). [DOI] [PubMed] [Google Scholar]
- 32.Capra JA, Williams AG & Pollard KS ProteinHistorian: tools for the comparative analysis of eukaryote protein origin. PLoS Comput. Biol 8, e1002567 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Pan J et al. Interrogation of mammalian protein complex structure, function, and membership using genome-scale fitness screens. Cell Syst. 6, 555–568.E7 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Yu H et al. High-quality binary protein interaction map of the yeast interactome network. Science 322, 104–110 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Kim DK et al. EVpedia: a community web portal for extracellular vesicles research. Bioinformatics 31, 933–939 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Hessvik NP & Llorente A Current knowledge on exosome biogenesis and release. Cell. Mol. Life Sci 75, 193–208 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Imjeti NS et al. Syntenin mediates SRC function in exosomal cell-to-cell communication. Proc. Natl Acad. Sci. USA 114, 12495–12500 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Calderone A, Castagnoli L & Cesareni G Mentha: a resource for browsing integrated protein-interaction networks. Nat. Methods 10, 690–691 (2013). [DOI] [PubMed] [Google Scholar]
- 39.Kiran M & Nagarajaram HA Global versus local hubs in human protein-protein interaction network. J. Proteome Res 12, 5436–5446 (2013). [DOI] [PubMed] [Google Scholar]
- 40.Yang L et al. Comparative analysis of housekeeping and tissue-selective genes in human based on network topologies and biological properties. Mol. Genet. Genomics 291, 1227–1241 (2016). [DOI] [PubMed] [Google Scholar]
- 41.Paulson JN et al. Tissue-aware RNA-Seq processing and normalization for heterogeneous and sparse data. BMC Bioinformatics 18, 437 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Bossi A & Lehner B Tissue specificity and the human protein interaction network. Mol. Syst. Biol 5, 260 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Barshir R, Shwartz O, Smoly IY & Yeger-Lotem E Comparative analysis of human tissue interactomes reveals factors leading to tissue-specific manifestation of hereditary diseases. PLoS Comput. Biol 10, e1003632 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Sahni N et al. Widespread macromolecular interaction perturbations in human genetic disorders. Cell 161, 647–660 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Reynolds JJ, Walker AK, Gilmore EC, Walsh CA & Caldecott KW Impact of PNKP mutations associated with microcephaly, seizures and developmental delay on enzyme activity and DNA strand break repair. Nucleic Acids Res. 40, 6608–6619 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Landrum MJ et al. ClinVar: improving access to variant interpretations and supporting evidence. Nucleic Acids Res. 46, D1062–D1067 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Bhatnagar S et al. TRIM37 is a new histone H2A ubiquitin ligase and breast cancer oncoprotein. Nature 516, 116–120 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Olivé M et al. New cardiac and skeletal protein aggregate myopathy associated with combined MuRF1 and MuRF3 mutations. Hum. Mol. Genet 24, 3638–3650 (2015). [DOI] [PubMed] [Google Scholar]
- 49.Novarino G et al. Exome sequencing links corticospinal motor neuron disease to common neurodegenerative disorders. Science 343, 506–511 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Yang X et al. Widespread expansion of protein interaction capabilities by alternative splicing. Cell 164, 805–817 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.